
證券時(shí)報(bào)網(wǎng)
2024-09-19 08:23


北京時(shí)間9月13日凌晨,OpenAI重磅發(fā)布全新AI大模型——o1模型。
據(jù)OpenAI官網(wǎng)介紹,這一模型“旨在花更多時(shí)間思考后再作出反應(yīng)。它們可以推理復(fù)雜的任務(wù),解決比以前的科學(xué)、編碼和數(shù)學(xué)模型更難的問(wèn)題”。不過(guò),今天在ChatGPT和大模型API中新發(fā)布的是該系列中的第一款模型,而且還只是預(yù)覽版——o1-preview(o1預(yù)覽版)。
事實(shí)上,此前外界曾流傳OpenAI正在研發(fā)新模型“草莓”和“獵戶座”,其中“草莓”具有更強(qiáng)的推理能力、擅長(zhǎng)解決復(fù)雜的數(shù)理邏輯問(wèn)題,而“獵戶座”則將基于“草莓”模型的能力,是“ChatGPT”的超強(qiáng)繼任模型。
OpenAI首席執(zhí)行官山姆·奧特曼在其個(gè)人社交平臺(tái)表示,“雖然o1的表現(xiàn)仍然存在缺陷,不過(guò)你在第一次使用它的時(shí)候仍然會(huì)感到震撼。”
OpenAI今天發(fā)布的o1模型雖然名字上與此前泄露的“草莓”不同,但功能、推理、性能等方面與外界揣測(cè)的基本一致。據(jù)了解,o1的推理模式的特別之處在于,在回答用戶問(wèn)題之前,o1會(huì)進(jìn)入擬人化思考模式,將問(wèn)題分解成更小的步驟,逐一解決,然后生成一個(gè)較長(zhǎng)的內(nèi)部思維鏈,這一推理模式也使得回答的內(nèi)容更加準(zhǔn)確。
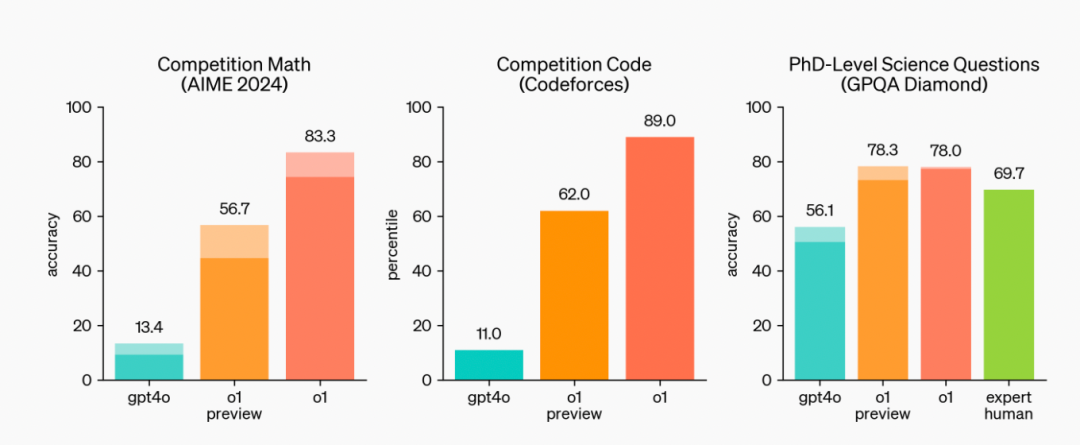
“在我們的測(cè)試中,下一個(gè)模型(o1模型)更新在物理、化學(xué)和生物學(xué)的具有挑戰(zhàn)性的基準(zhǔn)任務(wù)上的表現(xiàn)與博士生相似。我們還發(fā)現(xiàn)它在數(shù)學(xué)和編碼方面表現(xiàn)出色。在國(guó)際數(shù)學(xué)奧林匹克(IMO)資格考試中,GPT-4o僅正確解決了13%的問(wèn)題,而推理模型得分為83%。他們的編碼能力在比賽中得到了評(píng)估,并在Codeforces比賽中達(dá)到了第89個(gè)百分位。”O(jiān)penAI對(duì)o1模型的介紹表示。
在數(shù)學(xué)競(jìng)賽中,以AIME2024為例,GPT-4o平均只能解決12%的問(wèn)題,而o1平均能解決74%的問(wèn)題,若采用64個(gè)樣本的共識(shí),解決率能達(dá)到83%。o1在競(jìng)爭(zhēng)性編程問(wèn)題(Codeforces)中排名第89位,在美國(guó)數(shù)學(xué)奧林匹克(AIME)預(yù)選賽中躋身美國(guó)前500名學(xué)生之列,并在物理、生物和化學(xué)問(wèn)題(GPQA)基準(zhǔn)測(cè)試中超越人類博士級(jí)準(zhǔn)確度。
OpenAI表示,對(duì)于復(fù)雜的推理任務(wù)來(lái)說(shuō),這是一個(gè)重大進(jìn)步,代表了人工智能能力的新水平。鑒于此,OpenAI將計(jì)數(shù)器重置為1,并將該系列命名為OpenAIo1。
另外,OpenAI在過(guò)去一段時(shí)間一直被質(zhì)疑因加快產(chǎn)業(yè)開(kāi)發(fā)而降低了對(duì)模型安全的重視,團(tuán)隊(duì)中多名安全團(tuán)隊(duì)的人員也接二連三離職。對(duì)于模型的安全問(wèn)題,OpenAI表示,在開(kāi)發(fā)這些新模型的過(guò)程中,公司提出了一種新的安全訓(xùn)練方法,利用模型的推理能力,使它們遵守安全和協(xié)調(diào)準(zhǔn)則,能夠通過(guò)在上下文中推理安全規(guī)則,并且更有效地應(yīng)用這些安全規(guī)則。
“我們衡量安全性的一種方法是測(cè)試當(dāng)用戶試圖繞過(guò)安全規(guī)則(稱為‘越獄’)時(shí),我們的模型如何繼續(xù)遵循安全規(guī)則。在我們最嚴(yán)格的越獄測(cè)試之一中,GPT-4o得分為22(0-100分制),而我們的o1預(yù)覽模型得分為84。”O(jiān)penAI介紹稱。
適用對(duì)象方面,擁有增強(qiáng)的推理能力的o1模型更適合于解決科學(xué)、編碼、數(shù)學(xué)和類似領(lǐng)域的復(fù)雜問(wèn)題。例如,醫(yī)療研究人員可以使用o1來(lái)注釋細(xì)胞測(cè)序數(shù)據(jù),物理學(xué)家可以使用o1來(lái)生成量子光學(xué)所需的復(fù)雜數(shù)學(xué)公式,各領(lǐng)域的開(kāi)發(fā)人員可以使用o1來(lái)構(gòu)建和執(zhí)行多步驟工作流程。
除了o1系列模型外,OpenAI這次還一并發(fā)布了一個(gè)mini版OpenAIo1-mini模型。OpenAI在官網(wǎng)中給出了preview和mini版的不同定義,“為了給開(kāi)發(fā)者提供更高效的解決方案,我們也發(fā)布了OpenAIo1-mini,這是一個(gè)尤其擅長(zhǎng)編程的更快、更便宜的推理模型。”據(jù)了解,作為一款較小的模型,o1-mini比o1-preview便宜80%,使其成為一款功能強(qiáng)大、經(jīng)濟(jì)高效的模型,適用于需要推理但不需要廣泛世界知識(shí)的應(yīng)用程序。
至于新模型的使用方面,OpenAI稱,從發(fā)布之日起,ChatGPTPlus和Team用戶將能夠在ChatGPT中訪問(wèn)o1模型。o1-preview和o1-mini都可以在模型選擇器中手動(dòng)選擇。不過(guò),發(fā)送消息的次數(shù)目前還存在限制。o1-preview每周發(fā)送消息次數(shù)限制為30條消息,o1-mini則為50條消息。OpenAI稱正在努力提高這些發(fā)送次數(shù),并使ChatGPT能夠根據(jù)給定的提示自動(dòng)選擇正確的模型。
價(jià)格方面,API的價(jià)格上,o1-preview每百萬(wàn)輸入15美元,每百萬(wàn)輸出60美元。與之對(duì)比,GPT4o每百萬(wàn)輸入和每百萬(wàn)輸出分別是5美元和15美元,o1-preview價(jià)格是GPT4o的3倍。o1-mini會(huì)便宜一些,每百萬(wàn)輸入為3美元,每百萬(wàn)輸出為12美元。
關(guān)于未來(lái)的計(jì)劃,OpenAI表示計(jì)劃向所有ChatGPTFree用戶提供o1-mini訪問(wèn)權(quán)限。同時(shí),除了o1模型宣布的這些更新之外,OpenAI還希望添加瀏覽、文件和圖片上傳等功能,并計(jì)劃繼續(xù)開(kāi)發(fā)和發(fā)布GPT系列中的模型。
校對(duì):廖勝超






